항암 전, 암 교육실에서 설명을 듣고 있는데 갑자기 전화가 와서 골수검사를 해야 된다고 해서 얼른 듣고 병동으로 돌아갔다.
골수검사에 대해서 찾아보니 엄청 아프다는 사람도 있고 하나도 안아프다는 사람도 있고 누구의 말을 믿어야 할지 모르겠어서 그냥 에라이 모르겠다 하는 심정으로 엎드려 있으니 의사쌤이 마취를 하고 엉덩이 위를 도구로 뚫어서 골수를 채취하는데 엄청 아프진 않고 경상도말로 우~리~~하이 아픈 느낌이였다.
점심을 먹고 오후가 되어서 첫 항암을 시작하였다.
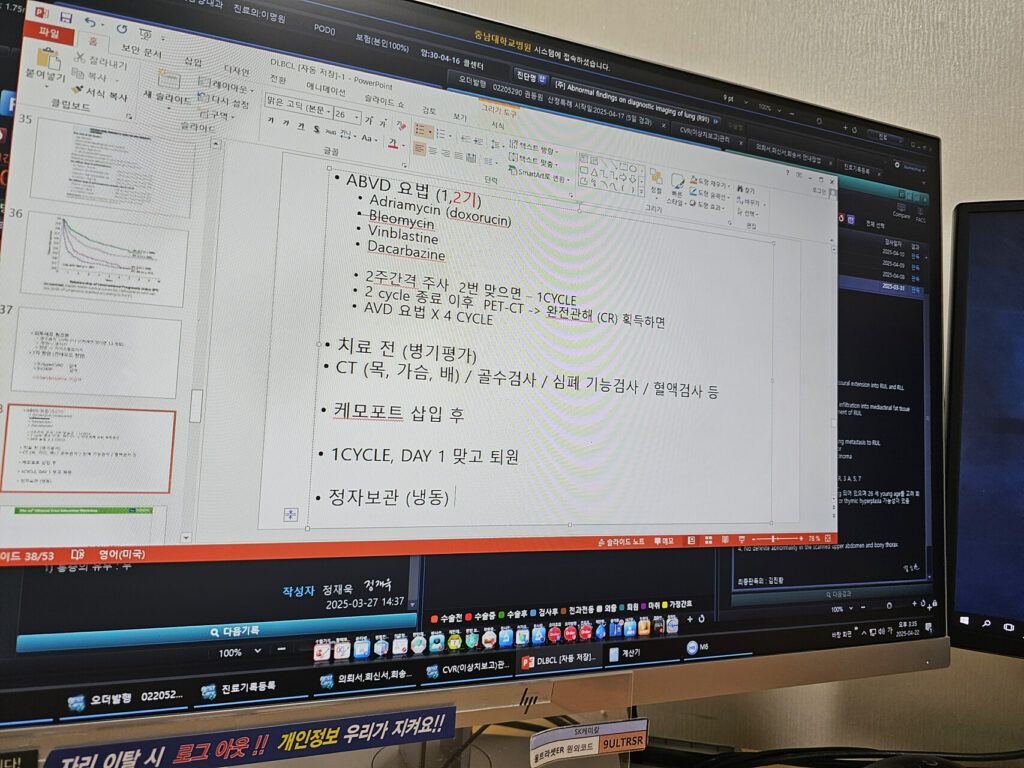
ABVD(아드리아마이신, 블레오마이신, 빈블라스틴, 다카르바진) 약을 투여하기 전에 스테로이드 주사를 맞았는데 온 몸이 찌릿하면서 전기가 통하는 느낌이였다.
import os
import glob
import cv2
import logging
from paddleocr import PaddleOCR
from datetime import timedelta
# 불필요한 내부 로그 숨기기
logging.getLogger("ppocr").setLevel(logging.ERROR)
def format_timedelta(td):
"""초(second)를 SRT 표준 시간 포맷(HH:MM:SS,mmm)으로 변환"""
total_seconds = int(td.total_seconds())
milliseconds = int(td.microseconds / 1000)
hours = total_seconds // 3600
minutes = (total_seconds % 3600) // 60
seconds = total_seconds % 60
return f"{hours:02d}:{minutes:02d}:{seconds:02d},{milliseconds:03d}"
def extract_chinese_subtitles(video_path, lang='ch', output_file='subtitles.srt'):
print(f"🔥 [{video_path}] 자막 추출 시작!")
ocr = PaddleOCR(use_angle_cls=False, lang=lang)
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
print(f"❌ {video_path} 동영상을 열 수 없습니다.")
return
fps = cap.get(cv2.CAP_PROP_FPS)
frame_interval = int(fps / 2)
frame_count = 0
current_text = ""
start_time = 0
subtitle_index = 1
# 'w' 모드로 파일 열기 (utf-8 인코딩 필수)
with open(output_file, 'w', encoding='utf-8') as f:
while cap.isOpened():
ret, frame = cap.read()
if not ret:
# 영상이 끝났을 때 마지막으로 화면에 있던 자막 기록
if current_text:
end_time = cap.get(cv2.CAP_PROP_POS_MSEC) / 1000.0
f.write(f"{subtitle_index}\n")
f.write(f"{format_timedelta(timedelta(seconds=start_time))} --> {format_timedelta(timedelta(seconds=end_time))}\n")
f.write(f"{current_text}\n\n")
break
if frame_count % frame_interval == 0:
height, width, _ = frame.shape
# 화면 하단 25% 영역만 크롭하여 OCR 인식 속도 및 정확도 향상
crop_h_start = int(height * 0.75)
cropped_frame = frame[crop_h_start:height, 0:width]
result = ocr.ocr(cropped_frame, cls=False)
frame_text = ""
if result and result[0]:
frame_text = "".join([line[1][0] for line in result[0]]).strip()
# 화면의 텍스트가 이전과 달라졌을 때 (새 자막 등장 or 자막 사라짐)
if frame_text != current_text:
current_time_sec = frame_count / fps
# 방금 전까지 화면에 있던 자막을 파일에 기록
if current_text:
end_time = current_time_sec
f.write(f"{subtitle_index}\n")
f.write(f"{format_timedelta(timedelta(seconds=start_time))} --> {format_timedelta(timedelta(seconds=end_time))}\n")
f.write(f"{current_text}\n\n")
subtitle_index += 1
# 새로운 자막 상태로 업데이트
current_text = frame_text
start_time = current_time_sec
# 터미널에도 진행 상황 출력
if current_text:
print(f"[{format_timedelta(timedelta(seconds=start_time))}] {current_text}")
frame_count += 1
cap.release()
print(f"🎉 추출 완료! '{output_file}' 파일이 생성되었습니다.\n")
# --- 메인 실행부 ---
if __name__ == "__main__":
# 현재 폴더에 있는 모든 .mp4 파일을 자동으로 찾아 리스트로 만듭니다.
video_files = glob.glob('*.mp4')
if not video_files:
print("❌ 처리할 MP4 파일이 현재 스크립트가 있는 폴더에 없습니다.")
else:
print(f"총 {len(video_files)}개의 파일을 순차적으로 작업합니다.\n")
print("=" * 50)
# for문을 사용하여 리스트 안의 파일을 하나씩 순차적으로 꺼내서 작업
for video_file in video_files:
# 파일 이름에서 확장자(.mp4)를 분리하여 원본 파일명만 추출
base_name = os.path.splitext(video_file)[0]
# 출력할 srt 파일 이름을 원본 영상 이름과 동일하게 설정 (예: 영상이름.srt)
output_srt = f"{base_name}.srt"
# 자막 추출 함수 실행
extract_chinese_subtitles(video_file, lang='ch', output_file=output_srt)
# 작업 구분을 위한 절취선 출력
print("-" * 50)
print("✅ 모든 영상의 자막 추출 작업이 성공적으로 완료되었습니다!")
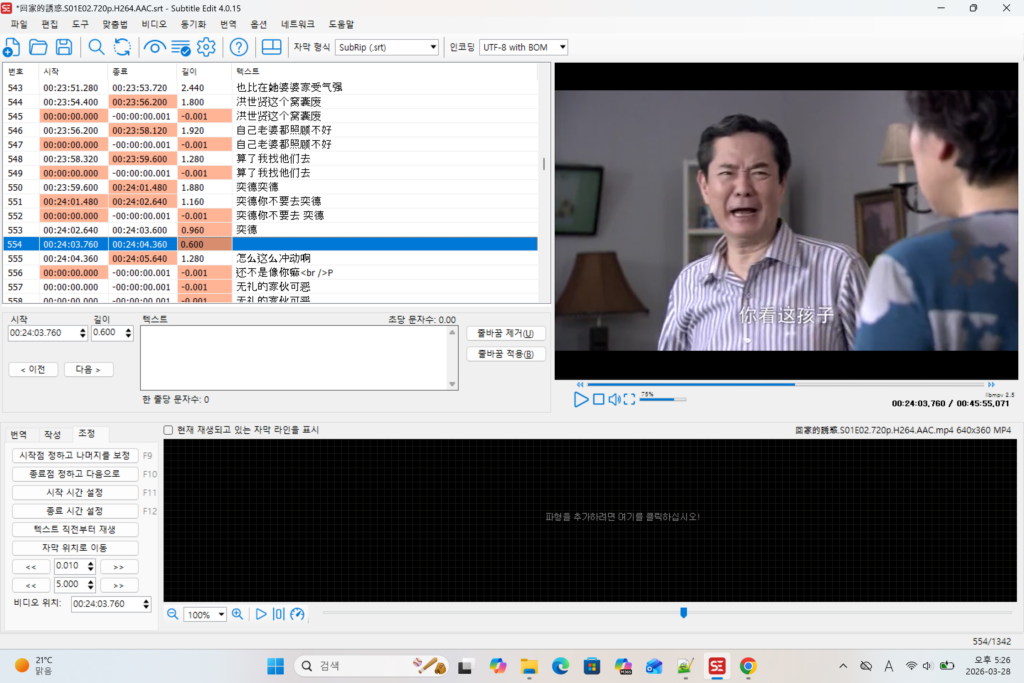
Paddle OCR 을 사용하니 EasyOCR 보다 속도도 빨라지고 인식률도 굉장히 좋아졌다.